

Advanced Micro Devices Inc. has launched the Instinct MI300 series data center AI accelerators together with the ROCm 6 software stack supporting large language models (LLMs).

AMD Instinct MI300 module, APU and platform specifications. Source: AMD.
As part of supporting documentation AMD has made bold claims for the MI300x’s ability to outperform Nvidia’s H100. AMD is claiming a 32 percent performance advantage for MI300x against Nvidia’s H100 across TensorFloat, floating point, block-float and integer data types compated with the H100. The H100 has 80Gbytes of HBM3 memory compared with the MI300X’s 192Gbytes.
It is also notable that the MI300X is made using TSMC’s 5nm and 6nm manufacturing process technologies while the H100 is made using the TSMC 4N process (4nm).
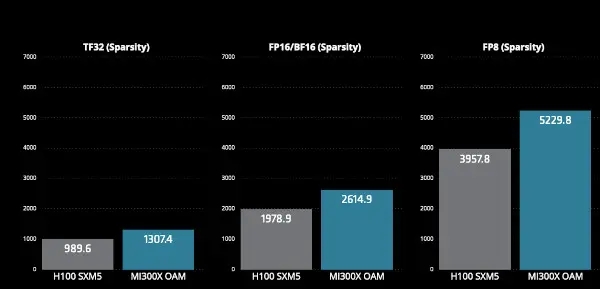
MI300X AI performance (Peak TFLOPs) by data type. Source: AMD.
The MI300 follows AMD’s CDNA3 GPU architecture and is manufactured using chiplets made using foundry TSMC’s 5nm and 6nm FinFET process technologies. The component has 19,456 stream processors and 304 computing units with maximum clock frequency of 2.1GHz. This provides peak FP16 performance of 1.3PFLOPS and peak INT8 performance of 2.6POPS.
The component is delivered on an OCP Accelerator Module (OAM) and uses passive cooling. The module includes 192 Gbytes of HBM3 memory with a peak theoretical memory bandwidth of 5.3Tbytes per second.
The ROCm 6 supports for new data types, advanced graph and kernel optimizations, optimized libraries and state of the art attention algorithms, which together with MI300X deliver approximately an 8x performance increase for overall latency in text generation on Llama 2 compared to ROCm 5 running on the MI250.
APU and platform
The AMD Instinct MI300A is an accelerated processing unit (APU) that has less Instinct accelerators but includes Epyc processors with shared memory to enable enhanced efficiency, flexibility, and programmability. They are designed to accelerate the convergence of AI and high-performance computing.
The MI300A includes 228 compute units and 24 Zen 4 x86 CPU cores together with 128Gbytes of HBM3 memory.
The AMD Instinct platform is a generative AI platform with eight MI300X accelerators to offer 1.5Tbytes of HBM3 memory capacity. Compared to the Nvidia H100 HGX, the AMD Instinct platform can offer a throughput increase of up to 1.6x when running inference on LLMs such as BLOOM 176B. AMD claims it is the only option on the market capable of running inference for a 70 billion parameter model, such as Llama2 on a single MI300X accelerator.
How much?
Nvidia’s H100 was previously recognized to be the highest-performing AI GPU processor for training and inference in data centers. According to Nvidia, the H100 set performance records in the industry-standard MLPerf benchmarks at 4.5x the performance of its own A100. The H100 is typically used for natural language processing, computer vision, and generative AI and can cost up between US$25,000 and US$40,000 according to reports.
The US government has decided both the H100 and A100 are too performant to be exported to China and some other countries without export licenses and given AMD’s performance claims it is to be expected the same restrictions will apply to the MI300 series.
“We are seeing very strong demand for our new Instinct MI300 GPUs, which are the highest-performance accelerators in the world for generative AI,” said AMD chair and CEO Lisa Su, in a statement. “We are also building significant momentum for our data center AI solutions with the largest cloud companies, the industry’s top server providers, and the most innovative AI startups who we are working closely with to rapidly bring Instinct MI300 solutions to market that will dramatically accelerate the pace of innovation across the entire AI ecosystem.”
At the launch event AMD referenced Microsoft, Dell Technologies, Hewlett Packard Enterprise, Lenovo, Meta, Oracle, Supermicro and others adopting AMD Instinct MI300x and MI300a data center AI accelerators for training and inference solutions.



